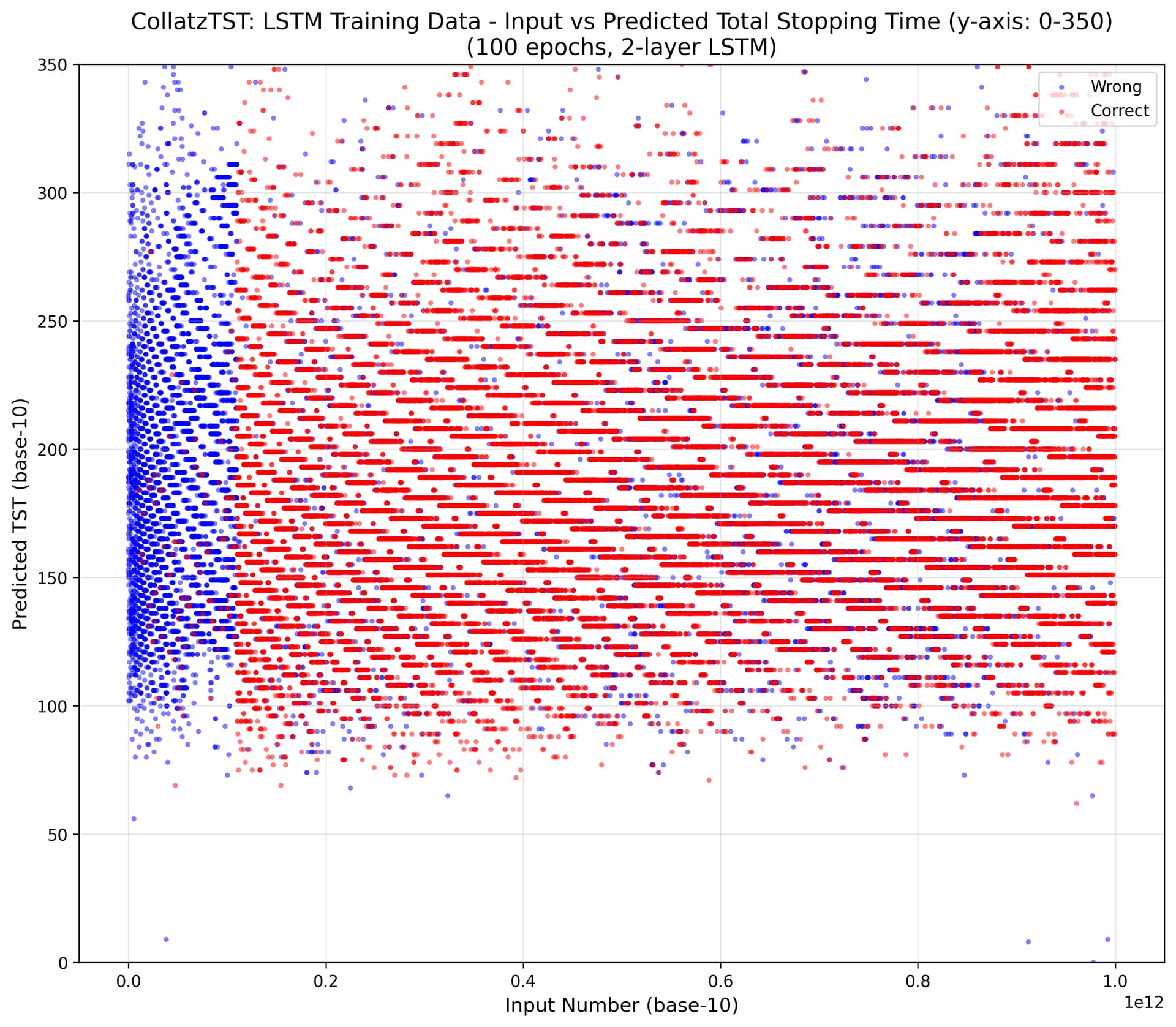
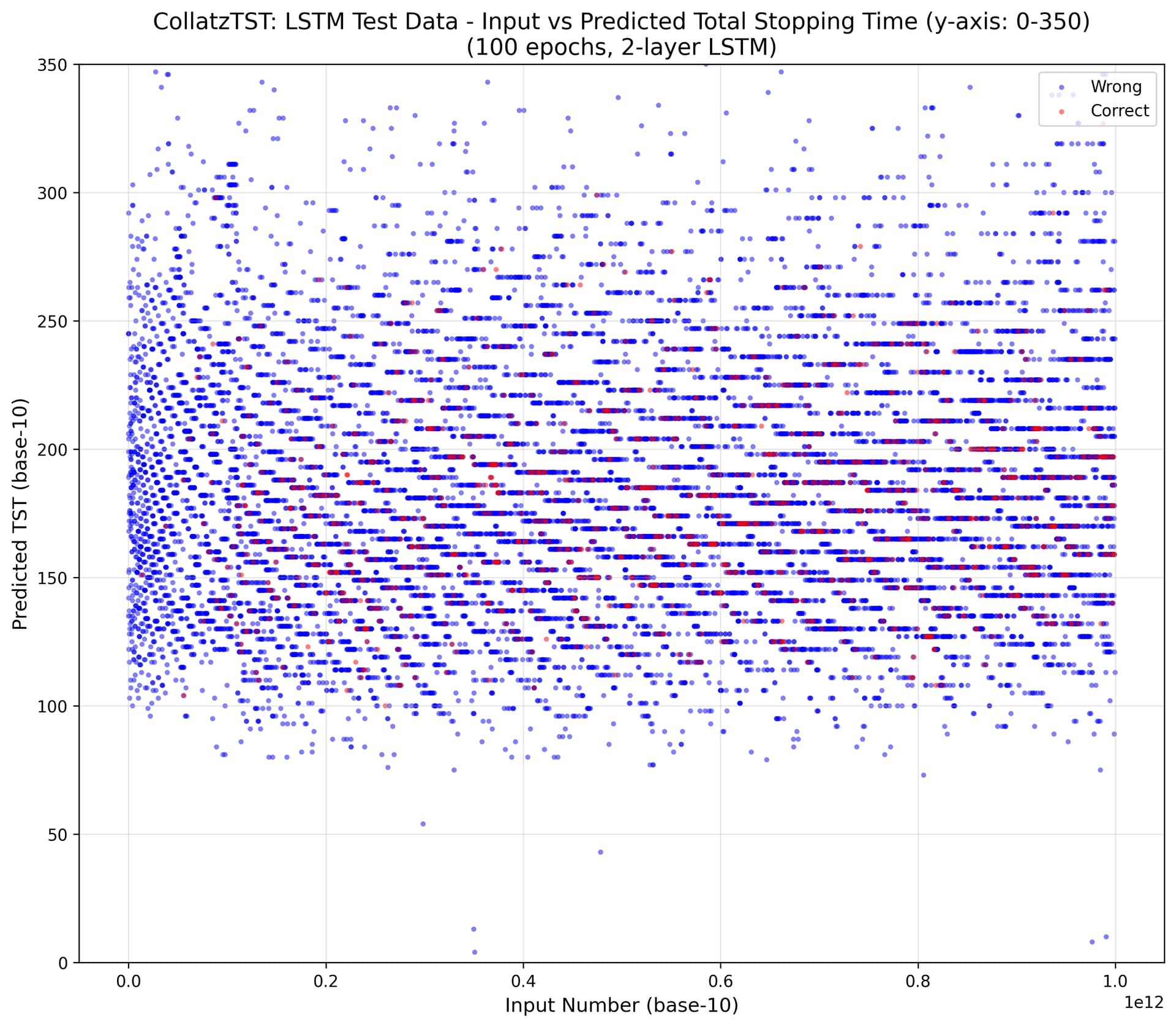
Some other ML runs on Collatz-related tasks.
Compute n mod 3:
| Base |
Examples |
Model Configuration |
Epochs |
Train |
Test |
| 6 |
10k |
LSTM (2-layer, h=128) |
50 |
100.00% |
100.00% |
|
|
Transformer (small) |
20 |
99.65% |
99.50% |
| 2 |
100k |
LSTM (2-layer, h=128) |
500 |
33.52% |
33.45% |
|
|
Transformer (small) |
50 |
33.69% |
33.51% |
|
|
Transformer (large) |
500 |
33.61% |
33.17% |
Can’t do n mod 3 on binary numbers. I thought the LSTM would have a fighting chance, since it works left-to-right, automata-like. But the ML systems seem to be on a wide flat plateau in which no small weight-change gets it any closer to action of the desired automaton.
Copy last 3 digits:
| Base |
Examples |
Model Configuration |
Epochs |
Train |
Test |
| 2 |
100k |
LSTM (2-layer, h=128) |
50 |
98.25% |
98.29% |
|
|
Transformer (small) |
20 |
95.27% |
95.00% |
Trivial task for debugging. Lightweight LSTM gets it faster and better.
Collatz Long Step:
| Base |
Examples |
Model Configuration |
Epochs |
Train |
Test |
| 24 |
100k |
LSTM (2-layer, h=128) |
50 |
63.58% |
54.57% |
|
|
LSTM (2-layer, h=128) |
300 |
73.15% |
55.73% |
|
|
LSTM (4-layer, h=128) |
300 |
85.94% |
70.23% |
|
|
Transformer (small) |
20 |
4.29% |
4.23% |
|
|
Transformer (large) |
20 |
21.82% |
21.70% |
|
|
Transformer (4-layer, d=512) |
20 |
67.35% |
67.14% |
|
|
Transformer (4-layer, d=512) |
100 |
81.85% |
79.48% |
Replicating the 2025 arXiv paper. Lightweight LSTM can do the job.
Collatz 5-type vs 16-type:
| Base |
Examples |
Model Configuration |
Epochs |
Train |
Test |
| 6 |
80k |
LSTM (2-layer, h=128) |
50 |
94.10% |
93.71% |
|
|
Transformer (small) |
50 |
93.78% |
94.00% |
|
|
Transformer (large) |
50 |
93.77% |
94.00% |
No better than chance.
Collatz total stopping time (TST)
| Base |
Examples |
Model Configuration |
Epochs |
Train |
Test |
| 24 |
100k |
LSTM (2-layer, h=128) |
100 |
53.06% |
6.04% |
|
|
Transformer (small) |
100 |
7.89% |
7.38% |
|
|
Transformer (small) |
500 |
8.84% |
7.80% |
|
|
Transformer (large) |
100 |
10.95% |
8.33% |
|
|
Transformer (large) |
400 |
22.01% |
7.70% |
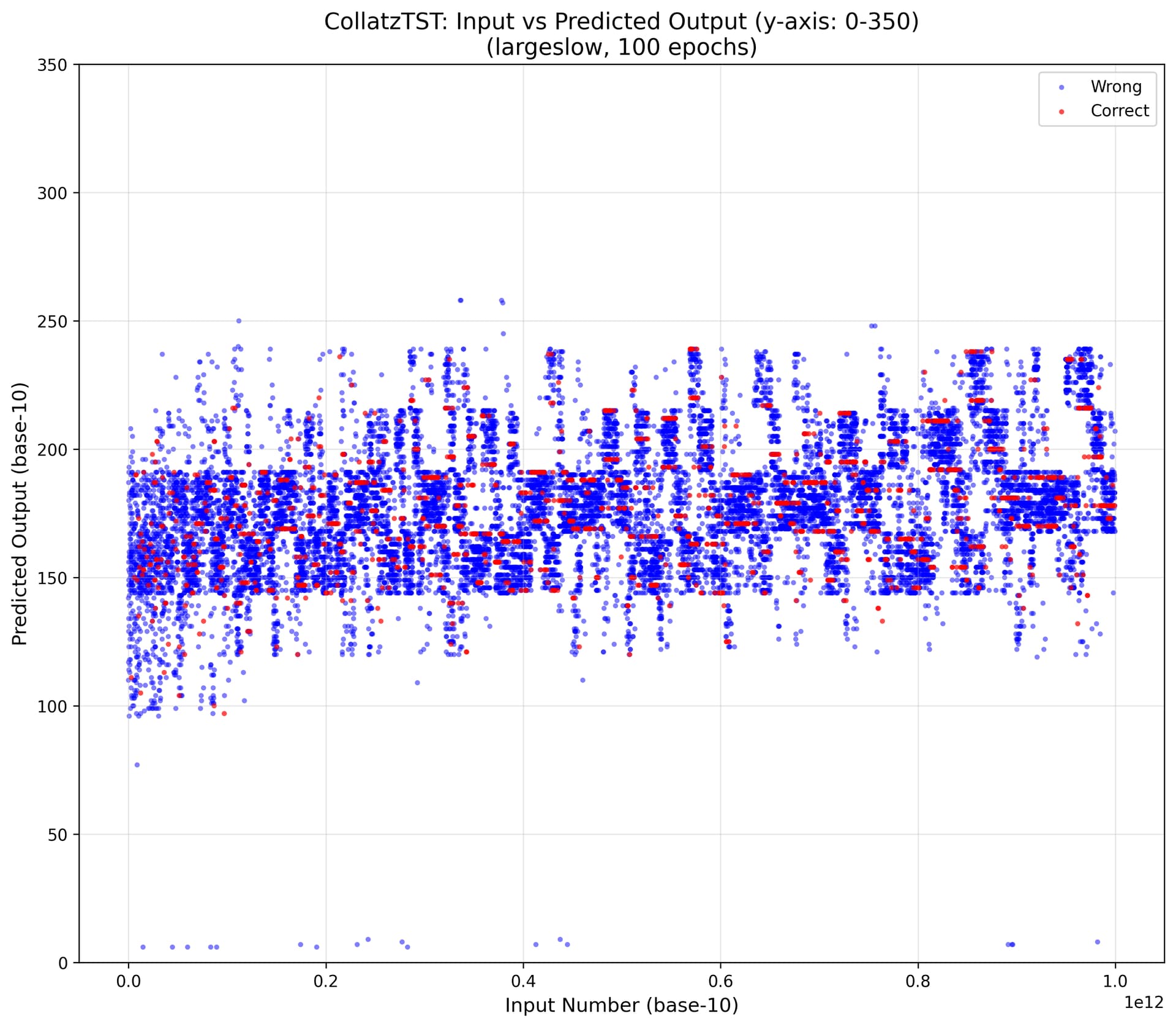
The TST results are in the ballpark of previous runs, though some prior settings (and possibly gradient descent luck) did obtain 12.3\% test-set accuracy.
Regardless, all runs immediately jump to \approx 8\% accuracy on both train and test sets.
I’m kinda interested in what that 8\% is.
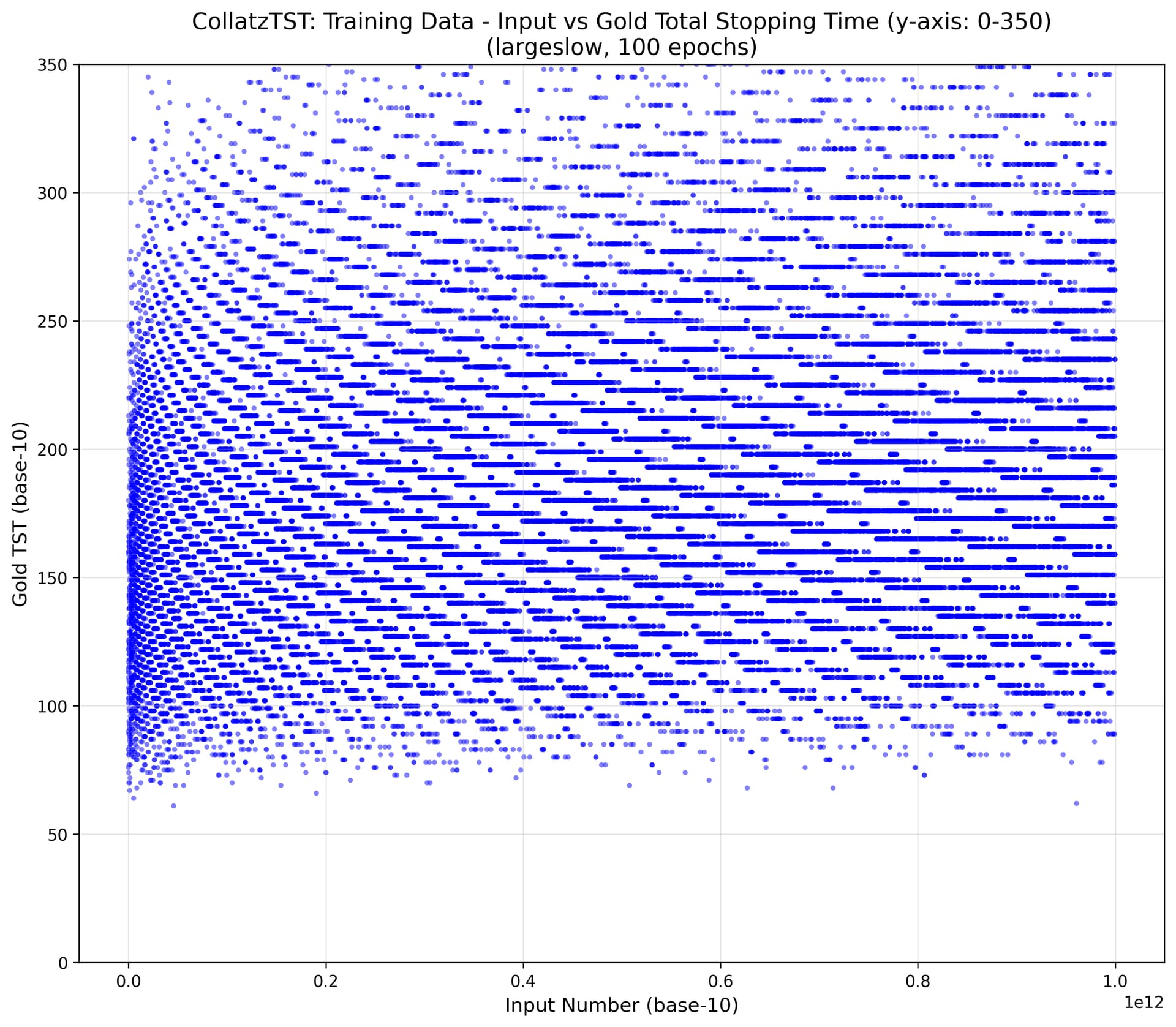
As @oros noted, even though the start numbers are drawn from 1 to 10^{12}, the TSTs are in a much smaller range. Their mean is 187 and stddev is 51.
The most common TST in the training data is 173 (in base 24, “7\ 5”). The baseline system “always guess 173” would only be correct in \frac{210}{20000} test cases, or 1.05\% accurate.
I wonder if there is some other simple baseline idea/program that would give 8\% test-set accuracy, or whether (by contrast) the ML system has learned something interesting.
The test set contains 336 unique TSTs, while the ML predictor (run on the same test set) yields a total 135 unique TSTs. The most frequently-output TSTs all begin with the base-24 digit 7, while the frequent gold answers are more diverse.